020 #glamhack


Photo by Axel Pettersson (Own work) CC BY 4.0, via Wikimedia Commons
The 2nd Swiss Open Cultural Data Hackathon at the beginning of July was two days of fun, innovation and digitally enhanced brainstorming hosted by the University library in Basel. Over a hundred people who appreciate Galleries, Libraries, Archives and Museums and wish to see the experiences of using their collections supported and enhanced by new media and technology at a very smoothly run event - kudos to Beat, Manuela, Lionel, and the entire team!
We aggregated data from providers onto the Data Tank (a storage device shared with participants for quickly transferring terabytes of data), ran a workshop and supported several teams with Q&A on Friday, and then worked on a text mining / art bot project for the remainder of the event. Here is a brief recount of the workshop. There is lots more to see on the wiki and Twitter!
Data, data, everywhere!
And yet... When is the last time data made a difference in your life? Have you taken the time today to think through the implications of all this machine-usable information to your self-confidence, critical faculties and overall success as a human being?
^ how our workshop - run by Jörg & Oleg - on Friday was described. We didn't know how many to expect, were not prepared for much more than 20, and so were somewhat overrun when about 35 people filled the workshop room, eager to find out about the School of Data and, ostensibly, learn something that would help boost their hackathon experience. We prepared some slides - in German as shown, similar in content to this earlier English version.
After our overview of the School of Data and how it fits into the landscape of open data portals, further education, data science, hackathons, and so on (we may have rambled a bit..), we asked our participants to fill in their Character Sheets. After a pause we asked people to show their sheets to their neighbours, then share their 'scores' with a show of hands. What our participants reported, orange being a strength (2 or 3), blue a weakness (0 or 1):
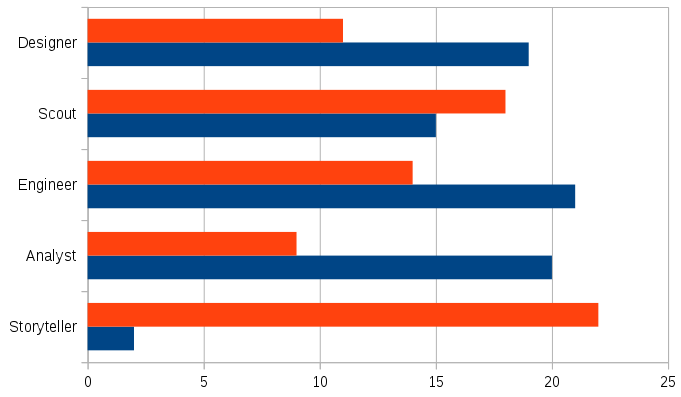
This was a lot of fun and people responded well to the idea of being adventurous with data and swapping roles to try something new and learn in the course of a Data Expedition. For the remaining minutes of the workshop we then dived into a quick tour of Open Refine, a free and open source Java-based toolkit for data cleaning that the School of Data supports - see Cleaning Data with Refine - and which can be downloaded here.
We prepared a demo based on a scraper of the Swiss parliamentarians database (morph.io), and showed some basic filters and facets. We explained how Open Refine keeps track of the "undo history" of the project in a way that is more portable and transparent than the usual desktop software - and why this may be important for activism and open data journalism.
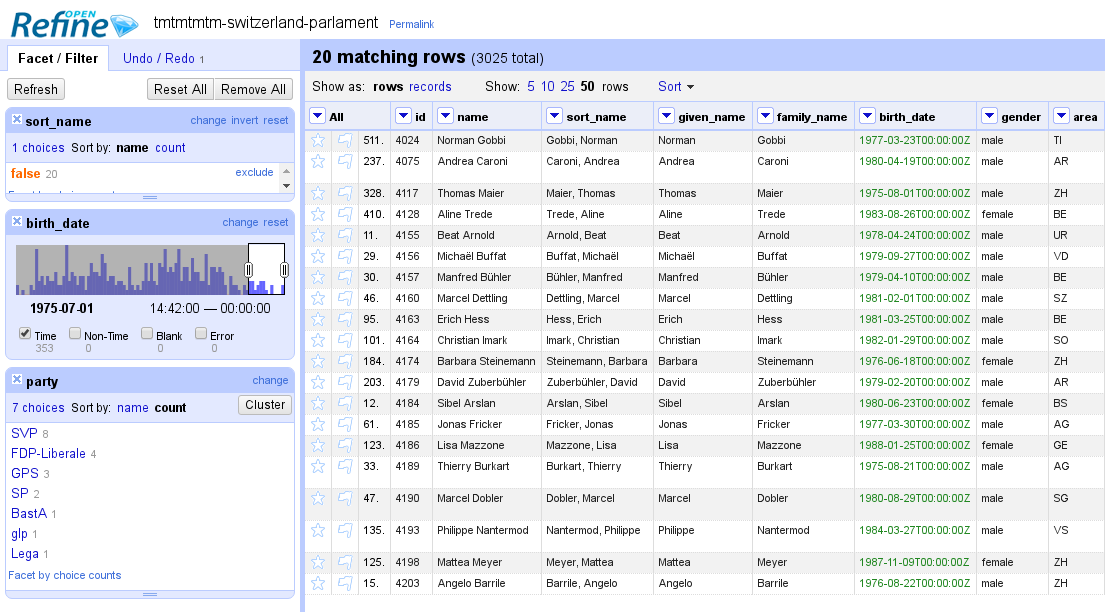
Open Refine screenshot showing the 20 youngest national councilliors and their parties.
This being not a very easy tool to use (we were stumped ourselves trying to remember a formula at one point, hunting around for the right menu item at another), and being rather dry in presentation (move along if you were expecting fancy info-graphics!), this part of the workshop was a bit drier. Next time we will aim to demo with more appropriate data, and more usable tools.
Speaking of which, during the workshop we called out to Software Carpentry, which just a week prior to the hackathon ran one of their first events in Switzerland and hosted their own introduction to OpenRefine for librarians, and the closely related Data Carpentry guide.

Screenshot from the Scrapy Cloud website
At the end of the workshop we mentioned our idea to collect some data about culture funding, and a couple of people joined me for a second hour to dive into the world of web scraping, something you can also learn more about from the School of Data here. We looked at Import.io, Morph.io and Beautiful Soup, all of which I have experience in, and settled on Scrapy, which I used for the first time... After a while of CSS mashing and RegExp bashing, we had our scraper that collects information from culturalpromotion.ch. We could have just asked for the data... but it was a good exercise! Source code at loleg/culturefunders-ch
Closing thoughts
One of the critical takeaways from the workshop for me was a comment about how our initiative relates to online courses. I responded saying that the School of Data set up MOOCs together with Peer2Peer University, and that I see many of the data and statistics courses out there as potentially awesome (and potentially daunting..) starting points into the science and art of data. It was clear from the short discussion that we should both embrace and support online study, and encourage offline study groups.

By Axel Pettersson (Own work) CC BY 4.0, via Wikimedia Commons
Another thing I realised is that in supporting transparent and open analytics through the use of OpenRefine or Jupyter, initiatives like ours could be playing an important role in spreading the ideas of shared learning and reproducible science. Both of the points above hasten my resolve to bring our platform forward in the near future.
Many thanks to everyone who turned out for the hackathon and our mini-data expedition! And massive thanks to Jörg for his work on the workshop, as well as to Daniel and Lorenz for our seriously fun dadabot project.
Would be glad to hear your feedback either on our forum or via oleg at soda.camp

{kind=link}
{kind=link}